How to properly blame things for causing latency
An introduction to Distributed Tracing and Zipkin
- Track: Testing and Automation devroom
- Room: UA2.220 (Guillissen)
- Day: Saturday
- Start: 16:30
- End: 17:15
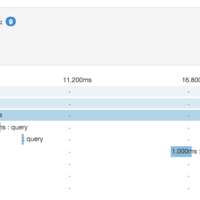
As architectures decompose into smaller pieces, figuring out the root cause of latency can become quite tricky. This session will review distributed tracing tools that can be used in your production systems to debug performance problems. While the focus is on Zipkin tools in practice, we'll also discuss related works.
Latency analysis is the act of blaming components for causing user perceptible delay. In today's world of microservices, this can be tricky as requests can fan out across polyglot components and even data-centers. In many cases, the root source of latency isn't a component, but rather a link between components.
This session will overview how to debug latency problems, using call graphs created by Zipkin. We'll use trace zipkin itself, setting up from scratch using docker. While we're at it, we'll discuss how the model works, and how to safely trace production. Finally, we'll overview the ecosystem, including tools to trace ruby, c#, java and spring boot apps. We'll wrap up with a look at simulation with Spigo and future works in Distributed Context Propagation.
When you leave, you'll at least know something about distributed tracing, and hopefully be on your way to blaming things for causing latency!
Speakers
| Adrian Cole |