Viterbi's little Helper
Coprocessor strategies for Forward Error Correction
- Track: Software defined radio devroom
- Room: AW1.125
- Day: Sunday
- Start: 12:30
- End: 13:00
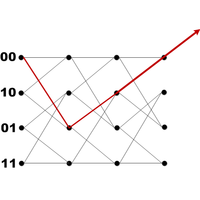
Forward Error Correction (FEC) is a vital part of every communication scheme. Convolutional Error Codes can provide the protection of the data to drive the communication system close to the Shannon Limit. But due to the complexity of the decoders, it is challenging to implement these algorithms in software for use in software defined radios (SDR). Available coprocessors, such as graphic processor units (GPU) and single instruction multiple data architectures (SIMD) can dramatically enhance the throughput of such software based receivers. Strategies to start implementing Viterbi- and Maximum A Posteriori (MAP) Decoders on these coprocessors are presented in this talk. Potential tripping hazards are identified. The effects on the throughput of these algorithms are analyzed and shown.
Convolutional Codes have been known for a long time. Viterbi established his algorithm to decode convolutional encoded data in the year 1967 [1]. SDR has also been established since the late 90’s and early 00’s. But still the implementation of convolutional decoders, such as the Viterbi- or MAP-algorithm, in software has always been a problem. Both algorithms rely on a Hidden Markoff Model as the encoder is simply a Mealy Machine. So if one surveys every possible state transition caused by a bit stream, a trellis structure is created. For every encoded information bit you have to consider all possible transitions from one state to another [1][2]. This leads to a high complexity and implementations of these algorithms suffer from a heavy computational burden.
The Viterbi Algorithm tries to relax these conditions by applying a dynamic programming approach to the trellis structure [3]. In this approach only the strongest path survives to reduce the overhead generated by analyzing all possible paths through the trellis. Still the computational effort is very high.
Up until now the technology used in SDRs has not been able to handle the computational burden of these algorithms. Implementations generally have suffered from a low throughput that was not suitable for state of the art communication systems (i.e. 3GPPP LTE or WLAN). Therefor these systems still used fixed hardware chips, such as ASICs, to manage the high throughput that these systems require.
With the increasing clock rates of General Purpose Processors (GPP) and the higher density of units inside the architecture, implementing these algorithms is starting to become more feasible. Especially additional architectural features such as SIMD architectures and multiple processor cores on one chip have gained increasing importance when implementing digital signal processing algorithms in software [4].
Another interesting field is the use of coprocessors found in common computers. In most cases this is going to be a GPU. GPU vendors also provide libraries and software development kits (SDK) to use the GPU for general computations and signal processing [5]. This specialized processors and libraries can be efficiently used to accelerate algorithms that can be massively parallelized.
This talk will cover implementation constraints that occur when implementing FEC and DSP algorithms on SIMD processors and GPUs. It will highlight some of the tripping hazard that newcomers have to avoid when trying to make an efficient use of these coprocessors. Exemplary cases for both architectures are analyzed to show, how the proper use of these architectures enhances a software defined communication system.
REFERENCES [1] A. Viterbi, “Error bounds for convolutional codes and an asymptotically optimum decoding algorithm,” Information Theory, IEEE Transactions on, vol. 13, no. 2, pp. 260–269, April 1967.
[2] L. Hanzo, T. H. Liew, and B. L. Yeap, Turbo Coding, Turbo Equalisation and Space-Time Coding for Transmission over Wireless Channels. Wiley, 2002.
[3] J. Forney, G.D., “The viterbi algorithm,” Proceedings of the IEEE, vol. 61, no. 3, pp. 268–278, March 1973.
[4] U. Santoni and T. Long, Signal Processing on Intel Architecture: Performance Analysis using Intel Performance Primitives, [Online]. Available: http://www.intel.com/content/dam/doc/whitepaper/ signal-processing-on-intel-architecture.pdf, 2014.
[5]NVIDIA: OpenCL Programming Guide for the CUDA Architecture, 2009. Version 2.3.
Speakers
| Jan Kraemer |